Datenreduzierende Audiocoder und MPEGplus-Projekt

Allgemeines zur irrelevanzreduzierenden Audiocodierung
Informationen, Software, Links zum MPEGplus-Projekt
Worum geht's:
Bei der Speicherung von Audio-Files im
CompactDisc-Format fallen hohe Datenmengen an - 44,1 kHz * 2 Kanäle
* 16 bit macht 1411,2 kbit/s oder etwa 10 MByte/min. Diese Codierung erfordert
zur Übertragung und Speicherung hohe Kapazitäten. Das Ziel der
datenreduzierenden Audiocoder ist eine Absenkung der Datenrate unter Beibehaltung
der hörbaren Qualität.
So lassen sich z.B. 74 Minuten Musik in
CD-Qualität auf Sony's MiniDisk (Kompression 1:4,8) unterbringen, oder aber es werden ".mp3"-Files bei meist jedoch schon wahrnehmbaren
Störungen durch eine Kompression auf ca. 1/11 geschrumpft.
Wie funktioniert's:
-
Der Nachteil der PCM-codierten (Pulse-Code-Modulation)
Signale besteht aus Sicht der Datenreduzierung zuerst darin, daß
im gesamten Frequenzbereich eine konstante Quantisierungsauflösung
verwendet wird.
-
Bei den weniger komplexen Kompressionsverfahren
(MPEG-1 Layer-1 und -2) wird daher das breitbandige Signal in mehrere
schmalbandige zerlegt und jedes einzelne im Zeitbereich quantisiert. Bei
den komplexeren (MPEG-1 Layer-3 und AAC) wird das Spektrum des Signals quantisiert.
Um nur mit den laut Psychoakustischem Modell notwendigen Rauschabständen
quantisieren zu können, werden die Abtastwerte (Layer-1 und -2) bzw.
die Spektralkoeffizienten (Layer-3 und AAC) als Gleitkommazahl dargestellt.
Der Pegel des Subbands bzw. der Spektrallinien wird durch den Exponenten
(Scalefactor) beschrieben, die Quantisierung wird nur auf die Mantisse
angewandt (Quantisierung).
-
Die größte Ersparnis läßt sich durch die Ausnutzung psychoakustischer Effekte erreichen. Diese wurden durch
Messungen an Testpersonen ermittelt und machen Aussagen über die Wahrnehmungseigenschaften des menschlichen Gehörs. Während der
Codierung läuft ein Modell des menschlichen Gehörs mit, welches abschätzt wo und in welchem Ausmaß der Coder Fehler machen darf,
so daß diese gerade nicht wahrnehmbar oder, falls Fehler unvermeidbar sind, zumindest am wenigsten störend sind.
-
Wenn man nun die Quantisierung der Samples innerhalb der Teilbänder oder die Quantisierung der Spektrallinien durch das
Psychoakustische Modell steuert, kann man den unterschiedlichen Frequenzbereichen unterschiedliche Quantisierungsauflösungen
zuordnen. Dies entspricht dem Hinzufügen von (hoffentlich) nicht wahrnehmbarem Rauschen zu dem Audiosignal.
-
Die Algorithmen zur Modellierung des menschlichen Gehörs und der Quantisierungssteuerung sind relativ zeitaufwendig. Trotzdem kann
man allen Ungeduldigen nur davon abraten irgendwelche "fast"-Option, die in vielen Encodern zu wesentlich geringeren Codierzeiten
führt, zu benutzen. Zeitersparnis an dieser Stelle führt fast immer zu einer (natürlich dauerhaft) schlechten Qualität der
Audiosignale.
Psychoakustik-Beispiele:
- Ruhehörschwelle:
Sie gibt an (gepunktete Linie), ab welcher Lautstärke das menschliche
Gehör einen reinen Sinuston wahrnehmen kann. Die Ruhehörschwelle
ist in den Psychoakustischen Modellen so normiert, daß ein Signal
im 16 bit-Format, welches eine Amplitude von +/- 1 aufweist, bei 0 dB der
Schwelle liegt. Hierin liegt ein (wenn auch nicht so gewichtiges) Problem,
da beim Encodieren niemand weiß wie laut später das codierte
Audiofile abgehört wird.

- simultane Maskierung:
Während einer akustischen Erregung wird die Hörschwelle abhängig vom Spektrum des Signals angehoben. Alle Signale unterhalb dieser
Schwelle - also auch Quantisierungsrauschen - werden nicht wahrgenommen.
Die simultane Maskierung ist der mächtigste Verdeckungseffekt. Im Psychoakustischen Modell werden zur Berechnung
verschiedene Schritte abgearbeitet:
- Kurzzeitspektralanalyse des Audiosignals per FFT
- der Prädiktionsfehler von Amplitude und Phase jeder Spektrallinie (unpredictability) wird berechnet; Ein geringer
Prädiktionsfehler deutet auf ein stationäres Verhalten (z.B. Sinus) dieser Spektrallinie hin.
- Zusammenfassung der spektralen Leistung innerhalb von Frequenzgruppen (vom menschlichen Gehör als zusammengehörig
empfundene Frequenzbänder)
- Spreading: Die Maskierung zwischen den einzelnen Frequenzgruppen wird durch die Spreadingfunktion beschrieben. Sie
modelliert die oberen und unteren Flanken der Maskierungsschwellen als nach "außen" hin fallende Geraden in dB/Bark. Die Steigung
dieser Geraden hängt sowohl von der Mittenfrequenz der Frequenzgruppen, als auch von der spektralen Leistung innerhalb dieser
Gruppen ab.
- Tonality measurement: Aus dem zuvor berechneten Prädiktionsfehler wird nun ein Faktor gewonnen, der ein Maß für die
Tonalität, also die "Sinusartigkeit", einer Frequenzgruppe darstellt. Dies ist notwendig, da bei sinusoiden Maskierern die
Mithörschwelle niedriger liegt als bei rauschartigen Maskierern. Dies bedeutet, daß Sinusoide mit höherer Auflösung quantisiert
werden müssen als Rauschen.
- Kombinieren des spreaded signal mit der tonality führt auf die Mithörschwelle (alle Störungen unterhalb dieser
Schwelle sind nicht mehr wahrnehmbar)
- Vergleich mit der Ruhehörschwelle: Falls die Mithörschwelle unterhalb der Ruhehörschwelle liegt, setze die
Mithörschwelle gleich der Ruhehörschwelle (threshold in quiet). Hierdurch ergibt sich die globale Mithörschwelle.
- Berechnung der notwendigen signal-to-mask-ratio(SMR), also dem mindesten Signalrauschabstand, mit dem diese
Frequenzgruppe quantisiert werden muß.
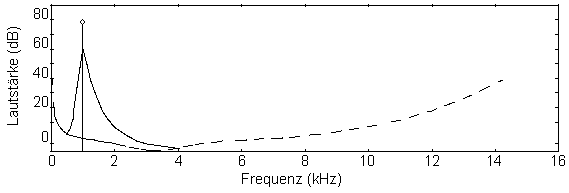
Mithörschwelle eines Sinustons bei 1 kHz
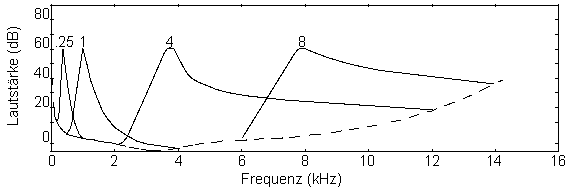
Mithörschwelle von 4 überlagerten Sinustönen
- zeitliche Maskierung: Die simultane Maskierung (s.o.) baut sich innerhalb weniger Millisekunden vor einem
Schallereignis auf und innerhalb von 100 - 200 ms wieder ab. Auch hier gilt, daß alle darunter liegenden Signale nicht
wahrgenommen werden können.
-
Pre-masking kann i.A. nicht zur Irrelevanzreduktion herangezogen werden, da dieser Effekt zeitlich sehr begrenzt ist.
Vielmehr läßt sich hiermit kontrollieren, ob sogenannte Preechos wahrnehmbar werden können. Diese entstehen, da die
Synthese-Filter (vor allem bei den MPEG-1 Layer-3- und AAC-Codern) eine begrenzte Zeitauflösung haben und diese somit das im
nächsten Frame auftretende Rauschen auch in den Zeitraum vor und nach diesem Frame "verschmieren".
- Post-masking läßt sich jedoch geringfügig reduzierend ausnutzen. Falls im letzten Frame gegenüber dem aktuellen Frame
eine höhere Mithörschwelle aufgetreten ist, kann diese trotz des "Absinkens" noch über der aktuellen liegen und dominiert somit
die Wahrnehmung.
Die Zeitkonstante der Nachmaskierung (Steilheit
der fallenden Mithörschwelle) hängt von der Dauer des zuvor aufgetretenen
Schallereignisses ab. Bei einer Schalldauer von mehr als 200ms tritt in
etwa der unten dargestellte Verlauf ein. Für kurze Schallereignisse
(z.B. Schlagzeug) fällt die Nachmaskierungsschwelle wesentlich schneller
ab, so daß in der Psychoakustik über mehrere Frames hinweg die
Dauer der Schallereignisse abgeschätzt werden muß.

Quantisierung:
-
Quantisierung am Beispiel eines Subbandcoders:
Die Reduzierung der Datenmenge beruht
auf einer durch die Maskierungsschwelle gesteuerten Quantisierung. Das
Prinzip soll die folgende Darstellung verdeutlichen.
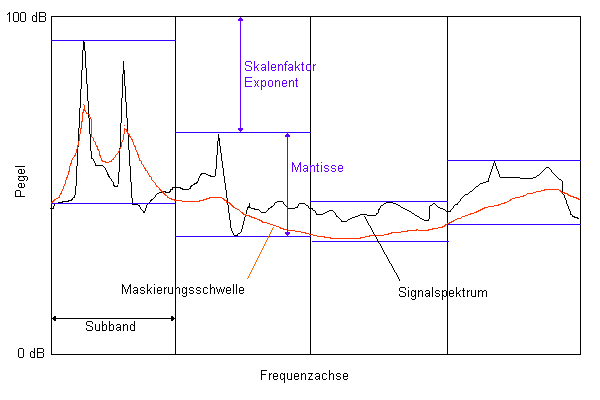
Bei einem Subbandcoder (z.B. MPEG-1 Layer-1 und -2) wird das Minimum der Maskierungsschwelle innerhalb eines Subbands
als Maximum der erlaubten Verzerrung interpretiert. Durch die Quantisierung
darf keine Rauschleistung größer als dieser maximal erlaubten
hinzugefügt werden.
Die Subbandsamples liegen in einer dem
Gleitkommaformat ähnlichen Zahlendarstellung vor. Hierbei wird
der absolute Pegel des Subbandsignals durch den Exponenten repräsentiert.
Der durch die Quantisierung zu erzielende Signalrauschabstand berechnet
sich aus dem 'Abstand' des Maximalpegels zur maximal erlaubten Verzerrung.
Dieser 'Abstand' wird als Signal-to-Mask-Ratio (SMR)
bezeichnet. Für nicht mehr wahrnehmbare Verzerrungen muß die
Quantisierung der Mantisse einen SNR > SMR erreichen. Die Quantisierungssteuerung
versucht nun für jedes Subband die minimale Quantisierungsauflösung
zu finden, welche diese Bedingung erfüllt.
Die sich hierbei ergebende Bitrate läßt
sich einfach abschätzen. Sie ist proportional der Summe der Flächen
SMR*Subbandbreite über alle Subbänder, wobei nur 'positive' Flächen
gezählt werden (Signalleistung liegt oberhalb der maximal erlaubten
Verzerrung). Wie in obiger Darstellung zu erkennen ist beträgt diese
Fläche nur einen Bruchteil der Gesamtfläche (Fläche der
PCM-Codierung).
Beispiel eines mittels Mithörschwelle
gesteuerten Audiocoders:
Die untere Graphik zeigt zum einen das
Kurzzeitspektrum eines Audiosignals (türkis) und zum anderen das von
einem Audiocoder (MPEGplus bei 128 kbit/s) hinzugefügte Rauschen
(pink).
Es ist deutlich zu erkennen, daß
ab ca. 17 kHz der Codierungsfehler gleich dem Signal ist, was nur bedeutet,
daß diese Frequenzanteile als nicht wahrnehmbar eingestuft und somit
nicht codiert worden sind. Weitherhin läßt sich leicht erkennen,
daß die hinzugefügten Verzerrungen der Form des Signalspektrums
folgen (ca. 6...9 dB Rauschabstand), bei tieferen Frequenzen aber gegenüber
den Peaks im Signalspektrum sehr gering ausfallen. Dies ist in den niedrigeren
erlaubten Verzerrungen bei sinusoiden Signalen begründet.
Wer sich noch weitergehend über Psychoakustik
informieren will, kann dies z.B. mit Hilfe des Buches "Psychoakustik" (E.
Zwicker, Springer Verlag) tun. Darin enthalten sind unter anderem die mathematischen
Zusammenhänge der auftretenden Effekte.
Wer sich mehr über den biologischen
Background des Hörvorgangs informieren möchte, sollte mal einen
Blick auf folgende Seite werfen: http://www.ossnet.uni-oldenburg.de/~fiedlerm/psychoakustik.html
(topic "Hörphysiologie"). Dort werden weitere Effekte (u.a Residuumeffekt,
räumliche Wahrnehmung, etc.) und die Grenzen des Gehörs (hat
meist sehr einleuchtende Gründe) erläutert.
So lautet der vorläufige Arbeitsname
für meinen Audiocoder. Der Encoder entstand während meines Studiums
"als Hobby", wobei die Motivation die damals (etwa 1997-1998) schlechte
Qualität von gängigen MP3-Encodern war. Mittlerweile hat der
Encoder hat eine recht hohe Qualität erreicht, die sich mit der von
MP3-Encodern messen kann.
MPEGplus basiert
auf dem Konzept der Teilbandzerlegung und gehört damit zu den sogenannten
Subband-Codern.
Die Besonderheit von MPEGplus ist
die stark getunte Psychoakustik, welche einen reinen VBR-Betrieb (variable
Bitrate) nahelegt. Ziel ist es, den Encoder mit default-Parametern zu einer
transparenten Codierung jedweder Audiosignale zu bringen, wobei nur die
Bitrate verwendet wird, welche für eine transparente Codierung notwendig
ist.
Allgemeines
zu MPEGplus:
Redundanzreduzierung (lossless coding):
-
Der MPEGplus-Encoder verwendet diverse
Huffman-Codes zur Redundanzreduzierung. Eine Huffman-Codierung findet für
die quantisierten Samples, die Skalenfaktoren sowie für die Frameheader
statt.
-
Ausnutzung der Korrelation von Skalenfaktoren
auf der Zeitachse
Irrelevanzreduzierung (Psychoakustisches
Modell):
-
Adaptive Noise-Shaping ANS:
Innerhalb der Teilbänder versucht der Encoder das Quantisierungsrauschen
so zu formen, daß es sich besser an die Maskierungsschwelle anschmiegt.
Dadurch wird mehr Rauschen zulässig, was wiederum die Bitrate senkt.
ANS verwendet Filter bis 5. Ordnung.
-
ClearVoiceDetection CVD:
Falls Vokale oder ähnliche harmonische Signale vorliegen, wird den
interessierenden Spektrallinien eine höhere Auflösung zugewiesen.
Dieses Verfahren behebt einige Probleme im psychoakustischen Modell hinsichtlich
der Erkennung von harmonischen Signalen (z.B Vokale der menschlichen Sprache).
-
Benutzung einer selbstgemessenen Ruhehörschwelle
(Switch "-ltq ank" bzw. "-ltq fil"); ist natürlich nur
sinnvoll bei ähnlichen Abhörbedingungen, bringt aber eine ganze
Menge, da das "ISO Standard-Gehör" bei hohen Frequenzen schon als
relativ schlecht angenommen wird !
-
Berücksichtigung von Aliasing zwischen
den Teilbändern bei der Berechnung der Signal-to-Mask-Ratio (SMR)
-
Die Spreadingfunktion, sie beschreibt die
Maskierungseffekte im Frequenzbereich, ist jetzt besser angepaßt.
Sie berücksichtigt nun auch die veränderliche Steilheit der oberen
Maskierungsflanke in unterschiedlichen Frequenzgruppen und bei variierenden
Schalldruckpegeln (Annahme eines maximalen Abhörpegels von 96 dB).
-
frameübergreifende Ausnutzung der Nachmaskierung
mit variabler Zeitkonstante (kurze Schallereignisse haben eine
kürzere Nachmaskierungsdauer als langanhaltende Schallereignisse)
Qualität
und Performance:
-
Bei Betrieb mit default-Parametern ("standard"-Profil)
erreicht der Encoder eine sehr hohe Qualität, die die von gängigen
MP3-Encodern (z.B. Lame) im Allgemeinen überbietet. MPEGplus
ist nahezu vollständig frei von Preechos oder Flanger-Artefakten.
-
MPEGplus arbeitet in Hinblick auf die
erzielte Qualität sehr stabil, d.h. mir sind nur sehr wenige, pathologische
Fälle bekannt, bei denen Veränderungen im Vergleich zum Original
wahrnehmbar sind.
-
Mit der aktuellen Version - Encoder mit StreamVersion 7 (SV7) - liegen die durchschnittlichen Bitraten bei etwa 160-170 kbit/s.
Bei unkritischen Signalen liegen die Bitraten nahe 100-120 kbit/s, bei
kritischen Signalen oberhalb von 200 kbit/s.
-
Der Encoder erreicht auf einem P3-800 derzeit
etwa 5,0-fache Echtzeit, das Winamp-plugin benötigt unter 1% CPU-Last
auf diesem Prozessor.
Download:
Sources:
- Source Code für Decoder: mppdec_source (ca. 36 KB, v1.7.8c) (23.06.2001) (veraltet)
- Source Code für Winamp-Plugin (english): in_mpp_source (ca. 54 KB, v1.7.9f) (veraltet)
- Source Code für Winamp-Plugin (deutsch): in_mpp_source (ca. 54 KB, v1.7.9f (deutsch)) (veraltet)
- Alternativer Decoder von Frank Klemm (irrsinnig schnell, Pentium III/K6-2/Athlon-Unterstützung)
Binaries:
Windows:
- Decoder: mppdec (ca. 50 KB, v1.7.8c) (23.06.2001) (veraltet)
- Encoder: mppenc (ca. 78 KB, v1.7.9c) (10.07.2001) (veraltet)
- Winamp-plugin (english): in_mpp (ca. 42 KB, v1.7.9f) (veraltet)
- Winamp-plugin (deutsch): in_mpp (ca. 42 KB, v1.7.9f (deutsch)) (veraltet)
Linux:
- Decoder: mppdec (ca. 28 KB, v1.7.8a) (veraltet)
- Encoder: mppenc (ca. 61 KB, v1.7.9a) (veraltet)
OS2:
- Player: mppplay (ca. 84 KB, v1.7.6) by Brian Harvard (http://silk.apana.org.au/utils.html)
Andere OS (diverse):
- Alternativer Decoder von Frank Klemm (irrsinnig schnell, Pentium III/K6-2/Athlon-Unterstützung)
Logos: logos.zip (ca. 78 KB)
Programme mit MPEGplus-Unterstützung:
Playback:
Winamp via plugin (http://www.winamp.com)
MediaJukebox via plugin (http://www.musicex.com/mediajukebox/)
DeliPlayer via plugin (http://www.deliplayer.com)
XMMS via plugin (http://sourceforge.net/projects/mpegplus/)
Batch-Encoding:
Easy CD-DA Extractor über
externen Encoder (http://www.poikosoft.com)
CDex über externen
Encoder (http://www.cdex.n3.net/)
EAC über externen
Encoder (http://www.exactaudiocopy.de)
Audiograbber über
externen Encoder (http://www.audiograbber.de)
Monkey's Audio über externen
Encoder (http://www.monkeysaudio.com)
MediaJukebox über externen
Encoder (http://www.musicex.com/mediajukebox/)
WinDAC32 über externen Encoder via Script
MP+ Frontend von M.Spüler http://www.mpegplus.de
FAQ:
Wenn ich mp+/mpc Dateien bei eingeschaltetem
Equalizer mit mp3 Dateien vergleiche, weisen die mp+/mpc Dateien einen
starken Höhenverlust auf.
Die Option "EQ controlled by WinAMP"
sollte deaktiviert sein. WinAMPs eingebauter EQ führt zu einem erheblichen
Höhenverlust ab 16 kHz und ist zusätzlich wesentlich CPU-intensiver
als der mp+ eigene.
Wenn ich mittels "-bw 22050" die Bandbreite
auf 22,05 kHz einstelle, behält die mp+ Datei dennoch nicht die volle
Bandbreite und "schneidet" typischerweise bei etwa 18,5 kHz ab.
Die Verwendung von "-bw x" stellt
nur
die maximal berücksichtigte Bandbreite für die Codierung dar.
Der Encoder speichert jedoch nur die Frequenzbereiche, die vom psychoakustischen
Modell als wahrnehmbar eingestuft wurden. Die Begrenzung der Bandbreite
arbeitet hierbei sehr umsichtig, so daß keine Unterschiede hörbar
werden sollten. Aus diesem Grund kann die resultierende Bandbreite von
der maximalen abweichen.
Für die Codierung der gesamten Bandbreite
ist der Parameter "-minSMR x" (x>0) oder einfach "-insane" (dieses Profil
beinhaltet die Codierung der vollen Bandbreite) zu verwenden.
Was ist die minimale und die maximale Bitrate
von mp+/mpc?
Der Encoder kann theoretisch bis
zu 1,32 Mbit/sec verwenden. Dieser Fall tritt aber i.A. nicht auf. Die
minimale Bitrate wird bei Nullsamples erreicht und liegt bei etwa 3,4 kbit/s
im "standard"-Profil.
Werden zukünftige Decoder/Plugins das derzeitige Bitstromformat weiter
unterstützen?
Ein klares Ja! Alle kommenden
Versionen werden die derzeit existierenden Formate (SV4 bis SV7) sowie
die Endung ".mp+" und ".mpc" unterstützen.
Wird MPEGplus bis zur "final version"
noch erhebliche Verbesserung der Qualität erfahren oder befindet sich
der Encoder bereits im Endstadium der Entwicklung?
Aus Sicht der Qualität befindet
sich MPEGplus infinitesimal entfernt von der endgültigen Version.
Die Änderungen bei einem Versionswechsel beziehen sich schwerpunktmäßig
nicht mehr auf den Encoder-Kern, sondern vielmehr auf Dinge wie Debugging
bei File-I/O und Parser.
Der derzeitige Encoder hat bei diversen
Tests durch mehrere User und unter Verwendung einiger hundert Musikstücke
seine Zuverlässigkeit in Bezug auf die Qualität bewiesen. Einzig
im direkten A/B-Vergleich über hochqualitative Kopfhörer und
unter großer Höranstrengung lassen sich bei wenigen Stücken
noch leichte Unterschiede zum Original hören. Bei keinem der encodierten
Musikstücke wurden auffällige Artefakte beobachtet.
Reicht die Verwendung des Profils "-standard"
aus oder sollte ich besser "-xtreme" oder gar "-insane" verwenden?
Der Encoder wurde im Profil "-standard",
d.h. für default-Einstellungen, intensiv getestet und optimiert. In
diesem Modus ist die Qualität der encodierten Stücke - trotz
der Profilbezeichnung - sehr hoch!
Das nächsthöhere Profil "-xtreme"
verwendet leicht modifizierte Parameter, um die Quantisierungsfehler noch
weiter unter die Wahrnehmungsschwelle zu drücken - es bietet also
noch mehr Reserve.
Im "-insane"-Profil werden die Parameter
nahezu krankhaft extrem eingestellt. Der Encoder speichert in diesem Modus
die volle Bandbreite und braucht wesentlich höhere Bitraten als im
"-standard"- oder "-xtreme"-Modus. Die Speicherung der vollen Bandbreite
hat keine psychoakustische Relevanz - der Mode wurde nur auf Wunsch einiger
User implementiert.
Fazit: Mit dem "-standard"-Profil ist
man schon auf der sicheren Seite. Wer noch ein wenig weiter gehen will,
benutzt "-xtreme". Die Verwendung von "-insane" ist generell nicht notwendig.
Wenn ich das File Stück von meiner
Lieblingsband.wav codieren will, bekomme ich die Fehlermeldung "ERROR:
File not found!".
Bei langen Dateinamen oder falls
Sonderzeichen enthalten sind, sollten die Dateinamen mit Anführungszeichen
angegeben werden: z.B. mppenc -v "Stück von meiner Lieblingsband.wav"
Wird es ein Windows ACM-Codec für
mp+/mpc geben?
Die Programmierung eines ACM-Codecs
ist generell nicht ausgeschlossen. Zur Zeit liegt der Schwerpunkt jedoch
auf Debugging und Erweiterung von Features. Ein ACM-Codec ist low priority.
Links:
Disclaimer:
Mit Urteil vom 12. Mai 1998 hat das Landgericht Hamburg entschieden, daß man durch die Ausbringung eines Links die Inhalte der gelinkten Seite ggf. mit zu verantworten hat. Dies kann - so das LG - nur dadurch verhindert werden, daß man sich ausdrücklich von diesen Inhalten distanziert.
Für alle auf diesen Seiten aufgeführten Links gilt:
Ich möchte ausdrücklich betonen, daß ich keinerlei Einfluß auf die Gestaltung und die Inhalte der gelinkten Seiten habe. Deshalb distanziere ich mich hiermit ausdrücklich
von allen Inhalten aller gelinkten Seiten auf meiner Homepage. Diese Erklärung gilt für alle auf meiner Homepage ausgebrachten Links und für alle Inhalte der Seiten, zu denen die Banner und Links führen.
 Andree.Buschmann@web.de
Andree.Buschmann@web.de